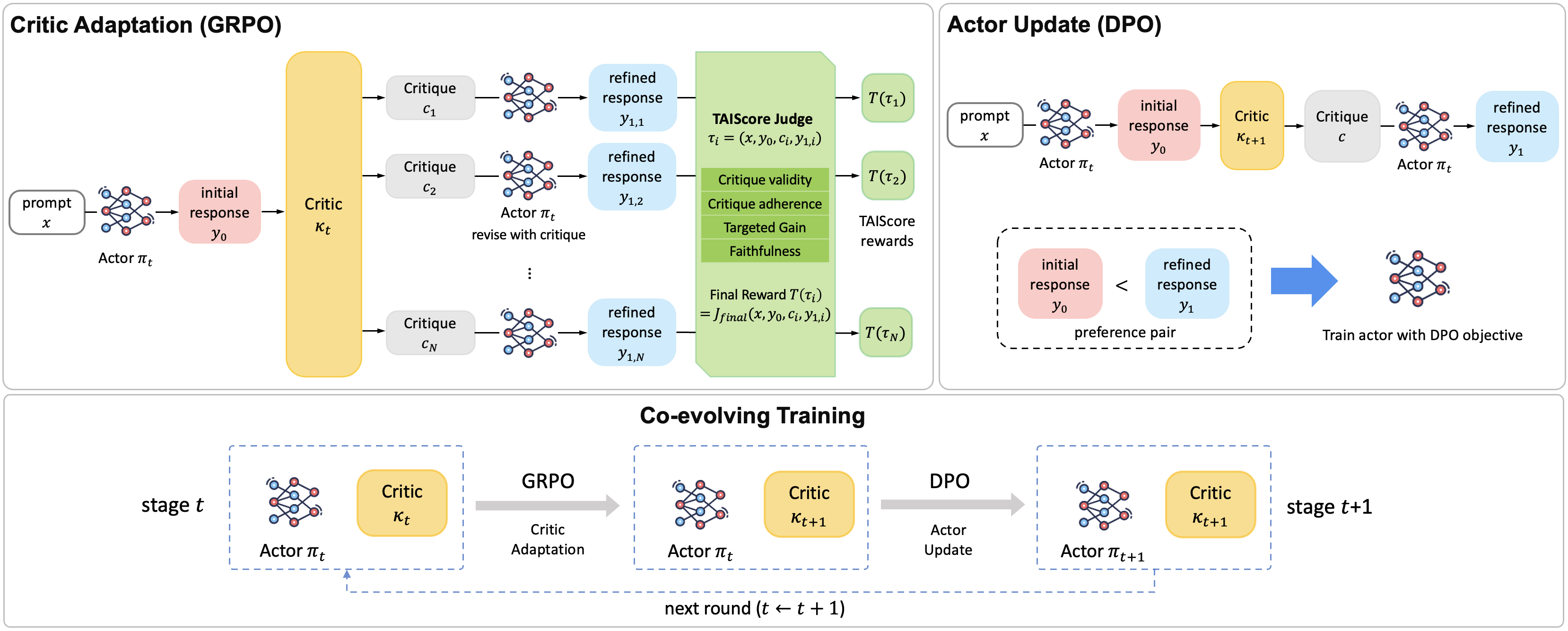
Critique Usefulness Is Actor-Conditioned
We conduct controlled analyses on WritingBench to test whether critique usefulness is intrinsic to the critique or conditioned on the actor. We find two key asymmetries: scaling the critic consistently improves standalone critique quality but does not reliably lead the actor to incorporate that feedback or yield larger downstream gains; while scaling the actor (with the same critique fixed) substantially improves both how well the actor follows the feedback and downstream quality. This confirms that critique usefulness is a property of the critique–actor pair, not the critique alone.
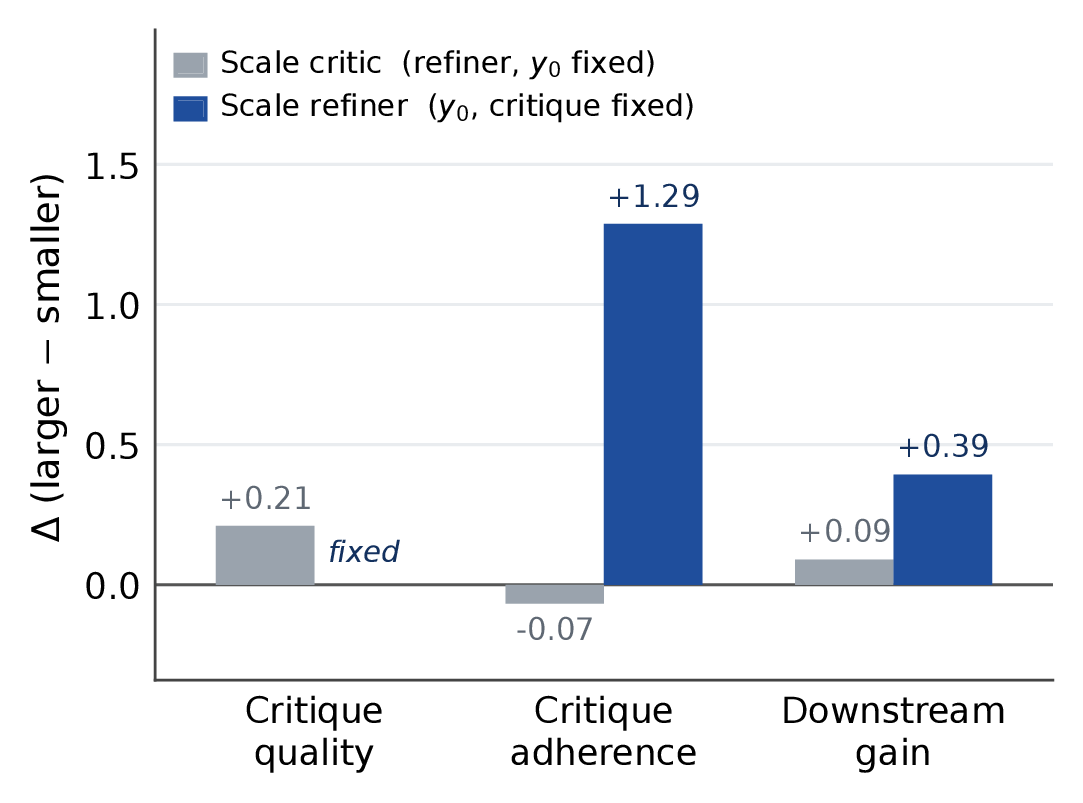
Controlled zero-shot analysis of critique-guided refinement, summarized as mean deltas over controlled comparisons. Critic quality measures standalone feedback quality. Critique adherence measures how well the actor incorporates the critique into its revision (rather than making unrelated edits). Gain is the downstream improvement S(y1)−S(y0) under the WritingBench evaluator. Scaling the critic improves standalone critique quality but does not reliably lead the actor to follow the feedback or yield larger gains. In contrast, scaling the actor while keeping the same critique fixed produces substantially larger improvements in both feedback uptake and downstream quality.